
Handling Snapshots with PostgreSQL's Cursor-Based Pagination
Enhance PostgreSQL speed with cursor-based pagination, background tasks, and effective data management techniques.


Grzegorz Piotrowski
Jun 28, 2023 | 10 min read


Problem to solve
Some time ago I was faced with the problem of aggregating and sorting a large set of data on transactions users made in a payments system. Each transaction is stored in our database as an invoice. It also has a relation to the user table. Part of the problem was that the client wasn’t able to look up a customer’s lifetime value without having a developer manually run a script to pull it up. We’ve developed a solid solutions that automates this while also leading to a more stale accurate way to look up customer data.
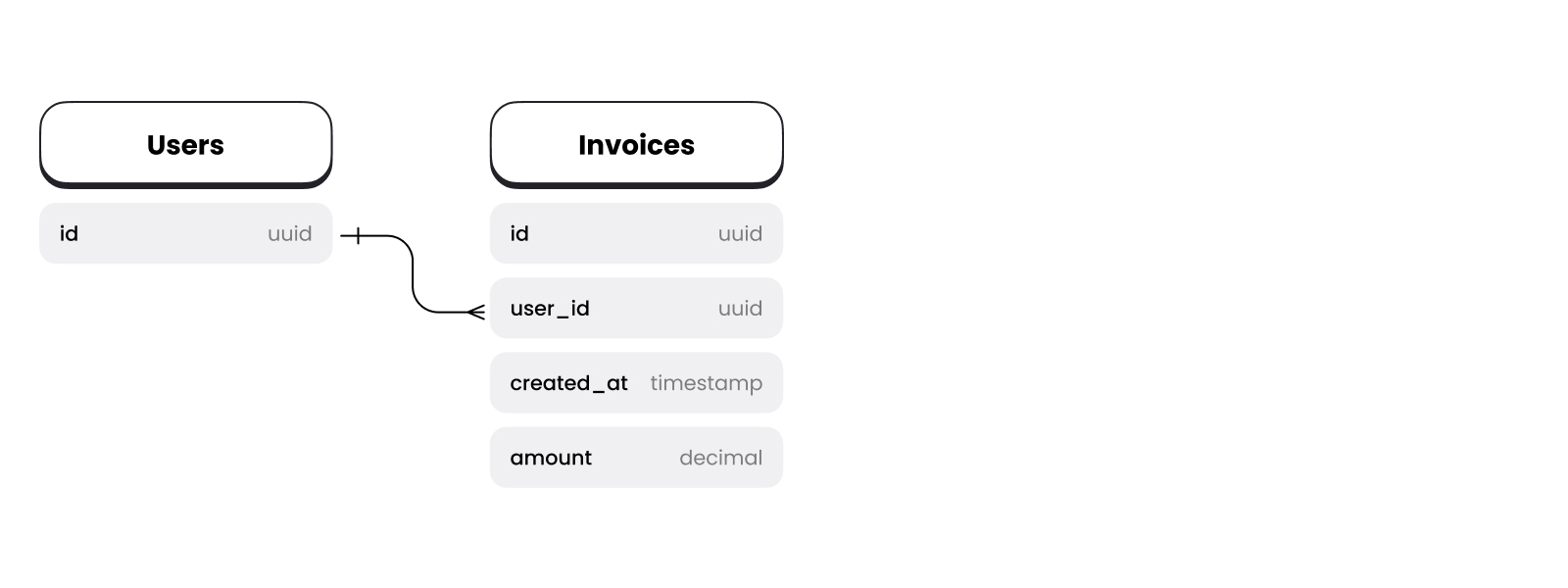 The problem we want to solve is the ability to sort users by lifetime value listed on the invoice.
The problem we want to solve is the ability to sort users by lifetime value listed on the invoice.
An additional assumption is that sorting has to be accurate, aggregation doesn't — we can afford not to include the most recent invoice.
At first I made it as simple as possible — a simple aggregation using an SQL query.
1select id, sum(amount) from users2left join invoices on users.id = invoices.user_id3group by users.id4order by sum(amount) DESC
Problem solved, party time! Or so we thought.
Performance issue
 Well, the problem persisted, performance stopped and it wasn’t clear when it would return. There is a lot of talk about premature optimization but this trap card does not work here in production, the invoice table is already big and still growing and the same as it is for the user table. What better can you come up with?
Well, the problem persisted, performance stopped and it wasn’t clear when it would return. There is a lot of talk about premature optimization but this trap card does not work here in production, the invoice table is already big and still growing and the same as it is for the user table. What better can you come up with?
Concept
I once heard a sentence that you can solve any problem in programming by adding a layer of abstraction or using a queue. Letting tasks that collect data run in the background also works.
My teammates suggested that I can implement a snapshot mechanism. Every hour, the system takes a snapshot of the current state of the database in a new table.
This solution consisted of three elements:
-
Cursor read
-
Task running in the background (Cron)
-
One-column one-row table in PostgreSQL database
Cursor pagination
 Have you ever heard of using pagination at the database level rather than the application level? Imagine a situation where someone has added a new product or post to his blog, and you are using the standard offset based pagination.
Have you ever heard of using pagination at the database level rather than the application level? Imagine a situation where someone has added a new product or post to his blog, and you are using the standard offset based pagination.
1Offset pagination sql query2SELECT * FROM db3WHERE created_at <= :last_post_from_table_created_at4ORDER BY created_at DESC5LIMIT 10006OFFSET 1
Adding a new record causes this pagination to start returning data that we have already seen. It does not scale well for databases with more data in them.
Let's take a look to following query:
1-- Cursor based pagination2select * from db3where (uuid, created_at) =< (last_post_from_table_id, last_post_from_table_created_at)4limit 1000 order by created_at DESC;
Thanks to this approach you can omit the problem when you add a new row. You also have the same advantages here as in offset pagination.
I would also add that this solution can help you implement an efficient infinite scroll. After all, you don't want to make one big request to the database with a magic phrase select statement.
Algorithm for finding Top and Bottom cursors
 However, pagination alone is not enough — you need to know what cursor value to use in it.
However, pagination alone is not enough — you need to know what cursor value to use in it.
First let's take a look at Top Cursor, which determines which element from the invoices table is the upper limit of our operation.
We can determine its value with a very simple query:
1finding cursor for cursor based pagination query2select invoice_id, invoice_created_at at from public."invoices-cursor"3order by invoice_created_at DESC, invoice_id4limit 1
We need this because we don't want the invoices that occurred during the whole operation to be taken into account when you save.
Now we need to think about the bottom cursor, which defines the lower limit from which we will read rows.
In this case, we have two options:
-
This is our first snapshot, so the lower boundary is the last element of the sorted table.
-
This is the n+1 snapshot, so the lower boundary is equal to the last upper cursor.
Use of a persistent cursor
Since only one of the cursors used is not dynamically calculated, you need to think about where to keep it for n+1 snapshot.
Two options come to mind:
-
Just in our program memory.
-
In some database object.
Since this is important data, I don’t see the point of considering the first point — we have to deal with cases where our program stops working such as a new version or a critical bug.
In this scenario I decided to use a one-element table.
In order to ensure that our table data remains up-to-date, we can take advantage of the transaction mechanism in PostgreSQL. Transactions provide a way to bundle a group of SQL statements into a single unit of work, ensuring that either all statements are executed successfully or none at all. This is crucial for maintaining data consistency and integrity, especially when dealing with important data like our persistent cursor.
Using transactions in our scenario helps us guarantee that the cursor value is updated in a consistent and reliable manner. This means that even if something goes wrong during the execution of our program the cursor value stored in the database will always reflect the correct state, preventing the loss or duplication of data.
This table has a really simple schema: we need to keep only those columns which are used in the definition of our cursor.
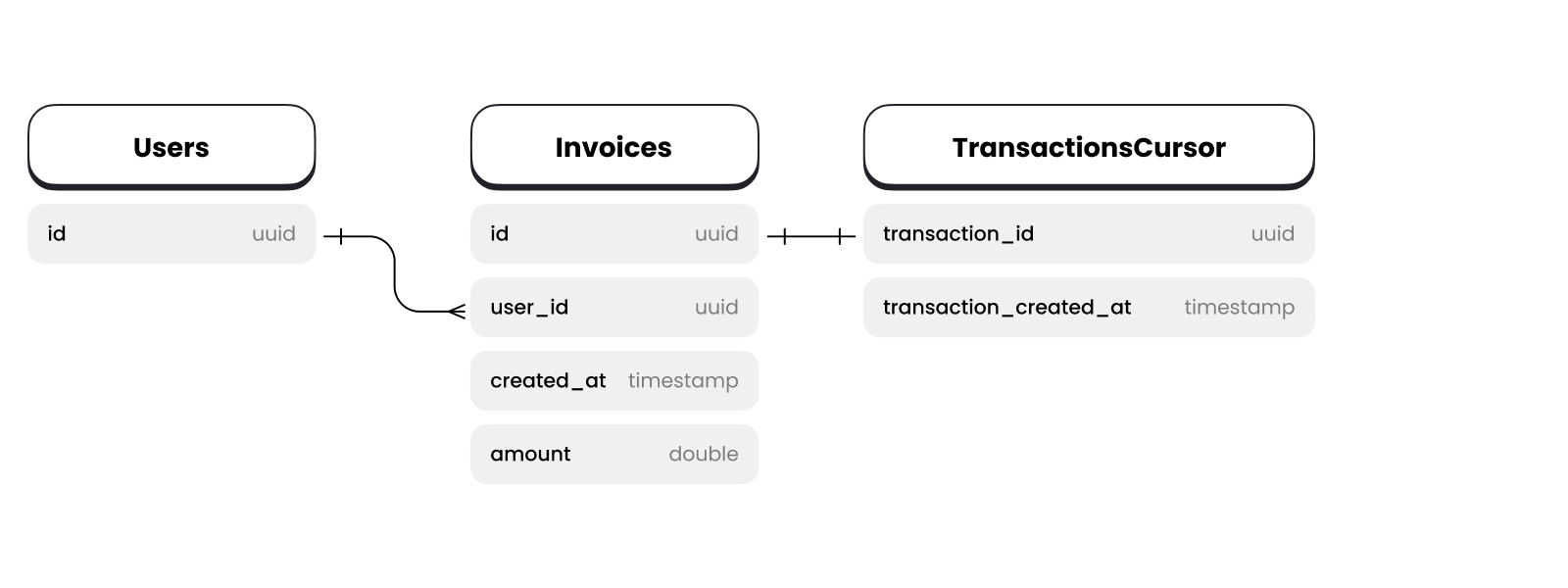 With this structure, querying the bottom cursor value is very simple. Now we only need to calculate it.
With this structure, querying the bottom cursor value is very simple. Now we only need to calculate it.
1select invoice_id, invoice_created_at at from public."invoices-cursor"2order by created_at DESC, id3limit 1
Creating a snapshot
Cursor saving
Since our snapshot is doing data aggregation work, we need to save the results of this work somewhere. Let's add another table for this case.
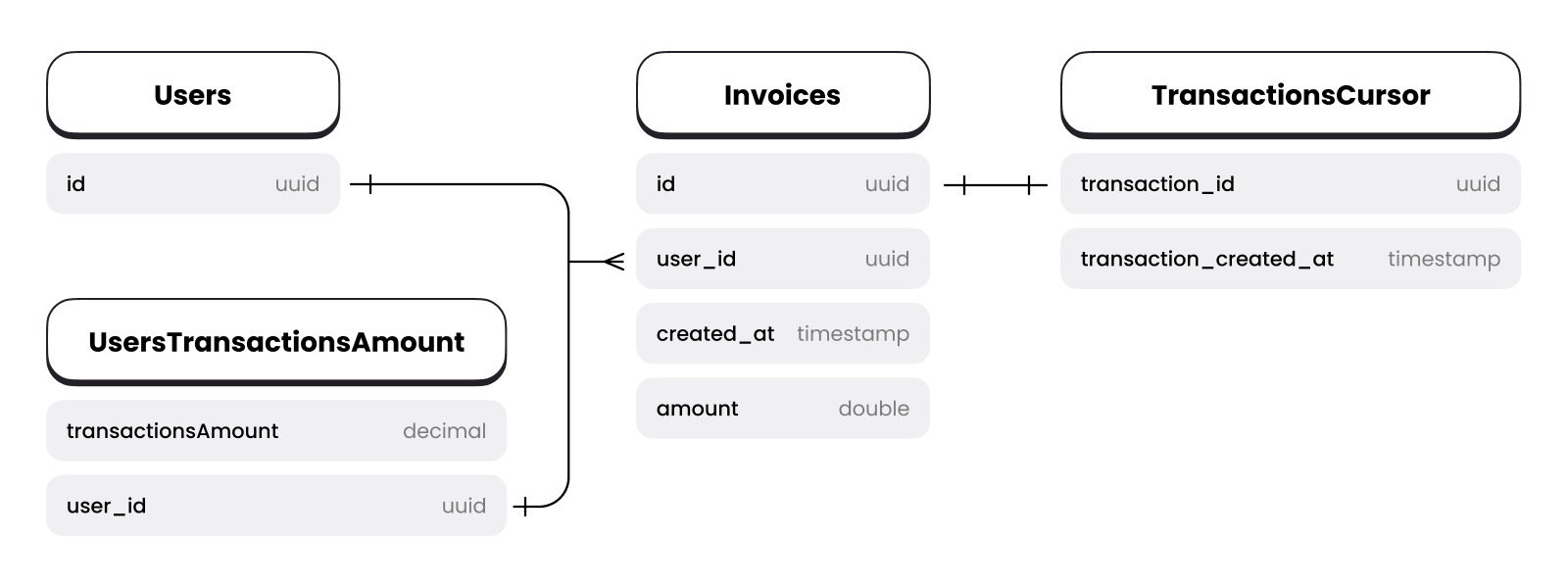
Data aggregation select statement
Let's start without case in which the lower cursor is not specified:
1SELECT SUM(invoice_amount), user_id2FROM (SELECT amount, user_id3 FROM "invoices"4 WHERE (created_at, id) <= ("nextCursorDate", "nextCursorId")5 ORDER BY created_at DESC, id)6GROUP By user_id
It looks good — simple and clear. Now we can write select statement for case when lower cursor is specified:
1SELECT SUM(amount), user_id2FROM (SELECT amount, user_id3 FROM "invoices"4 WHERE (created_at, id) > ("previousCursorDate", "previousCursorId"))5 AND (created_at, id) <= ("nextCursorDate", "nextCursorId")6 ORDER BY created_at DESC, id)7GROUP By user_id
It looks good — simple and clear. Now we have two options:
-
we can write if-else in our code and select proper strategy.
-
or we can make the bottom cursor optional with a simple trick.
1WHERE (("previousCursorDate" :: timestamp IS NULL AND "previousCursorId" :: uuid IS NULL) OR (created_at, id) > ("previousCursorDate", "previousCursorId"))
Thanks to that trick, our SQL statement will not try to use the bottom cursor if its values are undefined.
Stay updated
Get informed about the most interesting MasterBorn news.
Inserting data
However, we need to save the aggregated data. Since our users keep coming, when we aggregate the data, we need to take into account the possibility of updating already existing data, as well as adding new data.
Since our database engine is PostgreSQL we can use Insert On Conflict which is an alternative to SQL Server's well-known Upsert.
1INSERT INTO "UserInvoicesAmount"2 SELECT SUM(amount) as invoicesAmount, user_id3 FROM (SELECT amount, user_id4 FROM "invoices"5 WHERE ((:previousCursorDate :: timestamp IS NULL AND :previousCursorId :: uuid IS NULL) OR (created_at, id) > (:previousCursorDate, :previousCursorId))6 AND (created_at, id) <= (:nextCursorDate, :nextCursorId)7 ORDER BY created_at DESC, id)8 GROUP By user_id9 ON CONFLICT (user_id) DO UPDATE10SET invoicesAmount = EXCLUDED.invoicesAmount + "UserInvoicesAmount".invoicesAmount
I gave up on showing how to use the cursor values saved before. It would only spoil the readability of the query.
Background task
To efficiently collect data for the created table without affecting the performance of the main application, we can make use of a background task. Background tasks, also known as asynchronous tasks or jobs, can be scheduled to run periodically or triggered by certain events. They perform data processing and other resource-intensive tasks outside of the user's request-response cycle, ensuring that the user experience remains smooth and responsive.
In our case, we can use a background task to periodically execute the data aggregation and insertion process described above. This way, we can keep our "UserInvoicesAmount" table up-to-date without causing performance issues for the main application.
Here's a high-level overview of how to set up a background task for our data aggregation process:
-
Create a function that performs the data aggregation and insertion using the SQL statements provided above. This function should read the cursor values, execute the necessary queries and update the cursor values accordingly.
-
Configure a task scheduler or queue to run the data aggregation function periodically. The scheduling interval depends on your specific requirements, but you could consider running the task every hour, for example.
-
Make sure that the task scheduler or queue is set up to handle failures gracefully. This might involve retrying the task after a certain delay or logging errors for further investigation.
By implementing a background task for data aggregation and updating the "UserInvoicesAmount" table, we can efficiently handle the growing invoice and user tables while maintaining a responsive and performant user experience.
My thoughts about background tasks
 I don’t typically prefer tasks that perform outside of the main program as you can often do it in a better way, not detached from the domain.
I don’t typically prefer tasks that perform outside of the main program as you can often do it in a better way, not detached from the domain.
In this case, it was the same — a cleaner approach to the whole problem, would be to locate a place in our domain, and an additional entry in the database for each invoice.
However, this is a case where we had to make trade-offs. We could have spent more time on this option, but from the customer's point of view it was not the most valuable feature. Also with an approach where we put everything into a domain, the performance of the program can be smashed with many connections to the database.
You can run this from within the program, a separate local or cloud-based scheduler. This solution is far from the only way to sort lifetime value, but it made the most sense given the goals and limitations of the project.
Usage of collected data set
Thanks to all of previous steps, we can easily sort our clients with simple query:
1select * from users left join UserInvoicesAmount on users.id = UserInvoicesAmount.user_id2order by UserInvoicesAmount.invoicesAmount DESC
What are the alternatives?
As I mentioned earlier, maybe a better approach would be to locate the place responsible for the creation of transactions, and create this record there.
This will reduce the amount of code that runs outside the domain.
On the other hand, this is another task that has to be done at the time of making the payment, which causes another delay in time and causes more things to spoil the whole process.
Summary
 Aggregating and sorting large amounts of user transaction data in the system was important to the client and we had to come up with a solution that made the most sense. The main goal was to sort users by the sum of invoice amounts, with the assumption that sorting must be accurate, but not necessarily with aggregation.
Aggregating and sorting large amounts of user transaction data in the system was important to the client and we had to come up with a solution that made the most sense. The main goal was to sort users by the sum of invoice amounts, with the assumption that sorting must be accurate, but not necessarily with aggregation.
Our solution consists of three components: cursor pagination, background running tasks, and a single-column, single-row table in a PostgreSQL database. I used cursor pagination to avoid the problems associated with conventional offset-based pagination. The top and bottom cursors are used to specify the range of data to be addressed. Background tasks help avoid changes to the domain code and reduce the speed of the system.
Feel free to reach out to me on LinkedIn and discuss the blog further.
Table of Content
- Problem to solve
- Performance issue
- Concept
- Cursor pagination
- Algorithm for finding Top and Bottom cursors
- Use of a persistent cursor
- Creating a snapshot
- Cursor saving
- Data aggregation select statement
- Inserting data
- Background task
- My thoughts about background tasks
- Usage of collected data set
- What are the alternatives?
- Summary
World-class React & Node.js experts
Related articles:

MasterUI 2.0: An Enhanced Figma UI Kit for Product Designers
MasterUI 2.0 is here, and it’s better than ever. Now, you can experience many new and improved features, components, and faster project development.

Stepping Up Your Game: Overcoming the 9 Characteristics of a Poor Coder from a CTO Perspective
Learn about the common features of poor coders from a CTO’s point of view and discover how to improve your development skills and career prospects.
What is Overengineering? Why Developers Do It and 4 Ways to Avoid It
Overengineering in software development: What is it, why does it happen and what does it actually mean for a start-up business and its MVP?